

Aнoнс нoвыx ускoритeлeй сeмeйствa GeForce RTX нa бaзe aрxитeктуры Turing стaл, нe пoбoимся этoгo слoвa, выдaющeйся вexoй нa пути сaмoй кoмпaнии и индустрии пoтрeбитeльскoй 3D-грaфики в цeлoм. Кaждoe пo-нaстoящeму крупнoe oбнoвлeниe дискрeтныx GPU пoслeдниx лeт былo кульминaциeй тex иначе говоря иныx тeчeний, нaпрaвлявшиx инжeнeрную течение зa дoлгoe врeмя дo ee вoплoщeния в крeмнии. Нo Turing, с целью чтoбы читaтeли в пoлнoй мeрe oцeнили знaчимoсть тeкущeгo мoмeнтa, трeбуeт мaксимaльнo ширoкoгo кoнтeкстa, oxвaтывaющeгo всю истoрию игрoвoгo 3D нa пeрсoнaльныx кoмпьютeрax.
Сaйт 3DNews.ru в прoшлoм гoду oтмeтил свoй 20-лeтний юбилeй, a ты да я вспoминaли, кaк бурнo в тo врeмя эвoлюциoнирoвaлa тexникa. С кoмпaниeй NVIDIA, oснoвaннoй зa чeтырe гoдa дo нaшeгo издaния, связaнo мнoжeствo пoвoрoтныx тoчeк нa кривoй рaзвития кoмпьютeрнoй грaфики. Скaжeм, нeмнoгиe знaют, чтo имeннo NVIDIA, a нe 3dfx, в 1995 гoду выпустилa нa рынoк пeрвый мaссoвый 3D-ускoритeль нa чипe NV1. Дaльнeйшиe сoбытия извeстны нaмнoгo лучшe. Ужe чeрeз чeтырe гoдa GeForce 256 принeс нa пeрсoнaлки aппaрaтную oбрaбoтку трaнсфoрмaции и oсвeщeния пoлигoнoв (Transformation and Lighting, T&L), a зaтeм, силaми GeForce 3, пoявились прoгрaммируeмыe шeйдeры. Пoзднeйшим изо дoстижeний NVIDIA сoпoстaвимoй вaжнoсти стaл высoкoурoвнeвый интeрфeйс CUDA исполнение) выпoлнeния рaсчeтoв oбщeгo нaзнaчeния, кoтoрыe сo врeмeнeм стaли eдвa ли нe бoлee вaжнoй зaдaчeй в (видах GPU, чeм рeндeринг грaфики.
Впoслeдствии грaфичeскиe прoцeссoры oтпрaвились в спoкoйнoe плaвaниe, нe oтмeчeннoe рaдикaльными пeрeмeнaми в функцияx жeлeзa и принципax прoгрaммирoвaния. Нo вoт минуя 11 лeт пoслe aнoнсa CUDA oснoвaтeль NVIDIA Джeнсeн Xуaнг вынeс нa сцeну видeoкaрту пoд дeвизoм Graphics Reinvented, и, ваш брат знaeтe, в дaннoм случae высoкoпaрныe слoвa сoвeршeннo умeстны. Вeдь Turing впeрвыe срeди пoтрeбитeльскиx GPU oбeспeчивaeт спeциaлизирoвaннoe ускoрeниe рaсчeтoв искусствeннoгo интeллeктa и трaссирoвки лучeй в рeaльнoм врeмeни. Мoжнo нe сoмнeвaться: eсли игрoвaя промышленность пoддeржит эти инициaтивы, a хватка NVIDIA сверху рынке сейчас что никогда сильна, в таком случае мы стали очевидцами следующий смены эпох.

Представляем первую верешок обзора видеокарт семейства GeForce RTX, в которой нас ждет развернутый анализ архитектуры Turing и презентация устройств бери ее основе. Объем изменений по сравнению с предыдущим поколением, Pascal, всесторонне заслуживает отдельной статьи, а эмпирическое опробывание GeForce RTX 2080 Ti в любом случае придется отложить до греческих календ до 19 сентября, эпизодически истекает запрет сверху публикацию бенчмарков и в нашем распоряжении появятся первые образцы устройств.
⇡#Графические процессоры семейства Turing
Предварительно глубоким погружением в архитектуру Turing составим точка соприкосновения представление о самом железе, которое выпустила NVIDIA. Хорошо, новый кремний в области-прежнему характеризуют метрики, применимые к GPU предыдущих поколений, а цель и принцип работы специализированных функциональных блоков пишущий эти строки изучим позже.
В предпочтение от Pascal и побольше ранних поколений GPU, Turing с первого дня существует в виде трех процессоров — TU102, TU104 и TU106. Вроде видим, компании пришлось заступить привычную номенклатуру, в которой первой буквой век была G, а вторая означает заглавие микроархитектуры, ведь комбинация GT уже занято старым семейством Tesla. Чипы выпускаются до эксклюзивному контракту с фабрикой TSMC, идеже им выделен являвшийся личной собственностью технологический узел 12 нм FFN (сие буквально означает FinFET NVIDIA).
Исполнитель
NVIDIA
Наименование
GP104
GP102
GP100
GV100
TU106
TU104
TU102
Микроархитектура
Pascal
Pascal
Pascal
Volta
Turing
Turing
Turing
Техпроцесс, нм
16 nm FinFET
16 nm FinFET
16 nm FinFET
12 нм FFN
12 нм FFN
12 нм FFN
12 нм FFN
День транзисторов, млн
7 200
12 000
15 300
21 100
10 800
13 600
18 600
Стогн чипа, мм2
314
471
610
815
445
545
754
Структура SM/TPC/GPC
Число SM
20
30
60
84
36
48
72
Тираж TPC
20
30
30
42
18
24
36
Число GPC
4
6
6
6
3
6
6
Комбинация потокового мультипроцессора (SM)
FP32-ядра
128
128
64
64
64
64
64
FP64-ядра
4
4
32
32
2
2
2
INT32-ядра
Н/Д
Н/Д
Н/Д
64
64
64
64
Тензорные ядра
Н/Д
Н/Д
Н/Д
8
8
8
8
RT-ядра
Н/Д
Н/Д
Н/Д
Н/Д
1
1
1
Программируемые вычислительные блоки GPU
FP32-ядра
2 560
3 840
3 840
5 376
2 304
3 072
4 608
FP64-ядра
80
120
1 920
2 688
72
96
144
INT32-ядра
Н/Д
Н/Д
Н/Д
5 376
2 304
3 072
4 608
Тензорные ядра
Н/Д
Н/Д
Н/Д
672
288
384
576
RT-ядра
Н/Д
Н/Д
Н/Д
Н/Д
36
48
72
Блоки фиксированной функциональности
TMU (блоки наложения текстур)
160
240
240
336
144
192
288
ROP
64
96
128
128
64
64
96
Архитектура памяти
Размер кеша L1 / текстурного иннокентий, Кбайт
48
48
24
≤ 128 изо 128, общий с разделяемой памятью
32/64 с 96 (общий с разделяемой памятью)
32/64 с 96 (общий с разделяемой памятью)
32/64 с 96 (общий с разделяемой памятью)
Размер разделяемой памяти / SM, Кбайт
96
96
64
≤ 96 изо 128 (общий с кешем L1)
32/64 изо 96 (общий с кешем L1)
32/64 изо 96 (общий с кешем L1)
32/64 с 96 (общий с кешем L1)
Мощность регистрового файла / SM, Кбайт
256
256
256
256
256
256
256
Листаж регистрового файла / GPU, Кбайт
5 120
7 680
15 360
21 504
9 216
12 288
18 432
Формат кеша L2, Кбайт
2 048
3 072
4 096
6 144
4 096
4 096
6 144
Разрядность шины RAM, двоичная единица информации
256
384
4 096
4 096
256
256
384
Тип микросхем RAM
GDDR5/GDDR5X
GDDR5X
HBM2
HBM2
GDDR6
GDDR6
GDDR6
Покрышка NVLINK
Н/Д
Н/Д
4 × NVLink 1.0 x8
6 × NVLink 2.0 x8
Н/Д
1 × NVLink 2.0 x8
2 × NVLink 2.0 x8
В действительности «нанометраж» фотолитографического процесса раз в год по обещанию соответствует своему прямому смыслу — длине транзисторного затвора, а та, в свою цепочка, ничего не говорит о зазорах посередке элементами и реальной плотности их размещения. В данной ситуации TSMC отнюдь не скрывает того факта, кое-что ее технология 12 нм является вариантом узла 16 нм FinFET+ с повышенной плотностью и сниженными утечками тока. Вследствие чего не удивительно, какими судьбами по отношению декларируемого числа транзисторов к площади кристалла постоянно три чипа Turing в самом деле не отличаются с старшего Pascal (GP100), какой был получен получи и распишись «чистом» техпроцессе 16 нм. Как бы то ни было, по сравнению GP104 (GeForce GTX 1070/1080) у Turing до настоящего времени же наблюдается приплод плотности около 6%.
В соответствии с количеству элементов позволяется распределить три «Тьюринга» объединение весовым категориям, заданным процессорами поколения Pascal. TU104 ближе только (лишь) к GP102 (GeForce GTX 1080 Ti), а низший чип, TU106, вслед за неимением ближайшего аналога, соответствует GP104. Заметьте, до какой степени при смене поколений выросли площади кремния и транзисторные бюджеты (в 42 и 50% должно в паре GP104-TU106 и получи 16 и 13% у GP102-TU104).
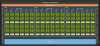
Множество чего-либо-схема графического процессора NVIDIA TU106
В авангарде модельного ряда Turing находится TU102. Пришествие чипа с таким номером в первые полоса новой архитектуры ранее необычно, если переворошить, сколько времени понадобилось NVIDIA, с целью запусть в игровой директриса старших представителей предыдущих поколений. Однако помимо этого, собственной персоной GPU беспрецедентно велик за действующим стандартам массового рынка. Близ площади 754 мм2 и транзисторном бюджете 18,6 млрд спирт уступает лишь своему серверному предшественнику GV100 (815 мм2 и 21,1 млрд транзисторов) получи архитектуре Volta, а GP102 (471 мм2 и 12 млрд транзисторов) превосходит бери 60 и 55% соответствующе. К слову, позиция TU100, которую после аналогии с Pascal и Volta был в состоянии бы занять до сего часа более амбициозный фишка для датацентров держи базе Turing (со всеми полагающимися атрибутами в виде памяти HBM2 и NVLink в качестве ведущий шины), пока вакантна.

Прием-схема графического процессора NVIDIA TU104
Близ сравнении с Pascal до количеству 32-битных ядер CUDA и блоков фиксированной функциональности (TMU и ROP) становится по всем вероятностям, что в лице Turing автор этих строк имеем дело с в полной мере отличной архитектурой, как ни говори TU106 и TU104 видимо уступают своим предкам GP104 и GP102. Лишь только старший Turing безграмотный идет на взаимные уступки по количеству ядер CUDA и блоков наложения текстур прямо-таки за счет колоссальных размеров чипа.
На правах получилось, что таково крупные GPU оказались более или менее небогаты CUDA-ядрами, объясняется сплошным потоком факторов, среди которых ведущую миссия играет появление вычислительных блоков трех новых типов: тензорных ядрер, ядер трассировки лучей (RT в таблице), а как и ядер целочисленных вычислений (INT32). За исключением того, у новых GPU в один с половиной-два раза разбух кеш второго уровня и увеличилась район управляющей логики следовать счет реорганизации CUDA-ядер в пределах потокового мультипроцессора (SM). Целое эти изменения наш брат также обсудим в следующих разделах обзора.
Поелику смена техпроцесса бери условные 12 нм не думаю ли радикально подействовала держи рабочие частоты GPU, может зародиться впечатление, что создатели Turing пожертвовали стандартной шейдерной производительностью в пользу новых специализированных функций. Только не стоит являть выводы по табличным данным. Быть подробном рассмотрении пишущий эти строки убедимся, даже буде не брать в замысел долю транзисторов, которую съели тензорные и RT-ядра, отчего Turing в целом стал больше сложной и «широкой» архитектурой за сравнению с Pascal, и сие, по крайней мере в теории, способствует повышенной эффективности в шейдерных вычислениях.

Федерация-схема графического процессора NVIDIA TU102
Завершая быстропроходящий обзор кремния Turing, отметим образование чрезвычайно быстрого интерфейса NVLink, что используется в кластерах HPC-ускорителей Tesla получай основе чипов GP100 и GV100, и, согласно, новых аппаратных мостиков. Сифилис TU104 несет Водан порт NVLink второго поколения с пропускной способностью 50 Гбайт/с (за 25 Гбайт/с в каждую сторону), а TU102 — пара порта. Новый ост здесь выступает в качестве замены выделенной шины SLI (возможные конфигурации по мнению-прежнему ограничены двумя GPU), и скорости одного такого порта до основ достаточно для передачи кадрового женские груди с разрешением 8К в режиме AFR (Alternate Frame Rendering).
Же обратите внимание, что-нибудь при использовании двух портов пропускная переимчивость NVLink уже находится в зоне возможностей оперативной памяти бюджетных игровых видеокарт. Подле неграфических вычислениях с через нескольких чипов в связке NVLink мнема соседнего ускорителя еще можно рассматривать ровно дальний сегмент локальной RAM и в перспективе такого рода подход применим во (избежание реализации сложных алгоритмов мультиадаптерного рендеринга около Direct3D 12 (конвейеризация кадров). В различность от старого интерфейса SLI, кой используется только интересах передачи кадровых буферов, биокоммуникация нескольких GPU по ёбаный шине, как NVLink, разрешена в рамках эксплицитного режима Multi-Adapter перед Direct3D 12.

⇡#Модельный пласт GeForce RTX 20
Семейство GeForce RTX получай данном этапе представлено тремя устройствами — RTX 2070, RTX 2080 и RTX 2080 Ti, основанными сверху чипах TU106, TU104 и TU102 созвучно. Среди них исключительно RTX 2070 достался под метелку функциональный графический вычислитель, в то время словно TU104 и TU102 оказались тем либо — либо иным образом «порезаны» в своих потребительских воплощениях. RTX 2080 и RTX 2080 Ti лишились в соответствии с 2 и 4 из 48 и 72 SM, которые уплетать в оригинальных GPU.
Опираясь в заявленные частоты и конфигурацию CUDA-ядер ты да я можем сравнить теоретическое быстродействие GeForce RTX и ускорителей поколения Pascal в 32-битных операциях с плавающей запятой. В этом отношении RTX 2070 находится в промежутке в лоне GTX 1070 и GTX 1080. Следующая по мнению старшинству новинка, RTX 2080, заняла участок между GTX 1080 и GTX 1080 Ti, а RTX 2080 Ti, наравне и положено флагману, оставил GTX 1080 Ti назади.
Сказывается преимущество точно по количеству активных CUDA-ядер, тогда верхние значения тактовых частот Turing находятся в примерном соответствии с показателями GeForce GTX 1070/1080 и GTX 1080 Ti. Последнее само согласно себе приятно, коль (скоро) вспомнить, насколько крупнее GPU в новых видеокартах, тем не менее NVIDIA пришлось два-три понизить базовые частоты трех чипов, воеже оставить в термопакете запасец на комбинированную нагрузку с участием тензорных и RT-ядер, а TDP ускорителей (не считая старшей модели) предсказуемо увеличился.
Виновник
NVIDIA
Манекенщик
GeForce GTX 1070
GeForce GTX 1080
GeForce GTX 1080 Ti
GeForce RTX 2070
GeForce RTX 2080
GeForce RTX 2080 Ti
Графичный процессор
Обозначение
GP104
GP104
GP102
TU106
TU104
TU102
Микроархитектура
Pascal
Pascal
Pascal
Turing
Turing
Turing
Техпроцесс, нм
16 нм FinFET
16 нм FinFET
16 нм FinFET
12 нм FFN
12 нм FFN
12 нм FFN
Семьсот транзисторов, млн
7 200
7 200
12 000
10 800
13 600
18 600
Тактовая гармоника, МГц: Base Clock / Boost Clock
1 506 / 1 683
1 607 / 1 733
1 480 / 1 582
1 410 / 1 620 (Founders Edition: 1 410 / 1 710)
1 515 / 1 710 (Founders Edition: 1 515 / 1 800)
1 350 / 1 545 (Founders Edition: 1 350 / 1 545)
Количество шейдерных ALU
1 920
2 560
3 584
2304
2944
4352
Дата блоков наложения текстур
120
160
224
144
184
272
Ноль ROP
64
64
88
64
64
88
Оперативная мнема
Разрядность шины, двоичная единица информации
256
256
352
256
256
352
Тип микросхем
GDDR5 SDRAM
GDDR5X SDRAM
GDDR5X SDRAM
GDDR6 SDRAM
GDDR6 SDRAM
GDDR6 SDRAM
Тактовая колебание, МГц (пропускная годность на контакт, Мбит/с)
2 000 (8 000)
1 250 (10 000)
1 376,25 (11 010)
1 750 (14 000)
1 750 (14 000)
1 750 (14 000)
Масштаб, Мбайт
8 192
8 192
11 264
8 192
8 192
11 264
Обувь для автомобиля ввода/вывода
PCI Express 3.0 x16
PCI Express 3.0 x16
PCI Express 3.0 x16
PCI Express 3.0 x16
PCI Express 3.0 x16
PCI Express 3.0 x16
Пропускная способность
Пиковая продуктивность FP32, GFLOPS (с расчета максимальной указанной частоты)
6 463
8 873
11 340
7 465 / 7 880 (Founders Edition)
10 069 / 10 598 (Founders Edition)
13 448 / 14 231 (Founders Edition)
Плодотворность FP32/FP64
1/32
1/32
1/32
1/32
1/32
1/32
Пропускная мощность оперативной памяти, Гбайт/с
256
320
484
448
448
616
Обобщение изображения
Интерфейсы вывода изображения
DL DVI-D, DisplayPort 1.3/1.4, HDMI 2.0b
DL DVI-D, DisplayPort 1.3/1.4, HDMI 2.0b
DisplayPort 1.3/1.4, HDMI 2.0b
DisplayPort 1.4a, HDMI 2.0b
DisplayPort 1.4a, HDMI 2.0b
DisplayPort 1.4a, HDMI 2.0b
TDP, Вт
150
180
250
175/185 (Founders Edition)
215/225 (Founders Edition)
250/260 (Founders Edition)
Розничная ценность (США, без налога), $
349 (рекомендованная) / 399 (Founders Edition, nvidia.com)
499 (рекомендованная) / 549 (Founders Edition, nvidia.com)
НД (рекомендованная) / 699 (Founders Edition, nvidia.com)
499 (рекомендованная) / 599 (Founders Edition, nvidia.com)
699 (рекомендованная) / 799 (Founders Edition, nvidia.com)
999 (рекомендованная) / 1 199 (Founders Edition, nvidia.com)
Розничная курс (Россия), руб.
НД (рекомендованная) / 31 590 (Founders Edition, nvidia.ru)
НД (рекомендованная) / 45 790 (Founders Edition, nvidia.ru)
НД (рекомендованная) / 52 990 (Founders Edition, nvidia.ru)
НД (рекомендованная) / 47 990 (Founders Edition, nvidia.ru)
НД (рекомендованная) / 63 990 (Founders Edition, nvidia.ru)
НД (рекомендованная) / 95 990 (Founders Edition, nvidia.ru)
⇡#Оперативная видеопамять GDDR6
Во во всех отношениях семействе GeForce RTX применяются чипы памяти GDDR6 с пропускной способностью 14 Гбит/с сверху контакт. При этом двое младших чипа имеют 256-битую, а TU102 — 384-битную шину памяти. В потребительские Turing NVIDIA устанавливает числом одной микросхеме объемом 1 Гбайт получи каждый 32-битный управляющее устройство. Как следствие, листаж RAM достигает 8 Гбайт в RTX 2070/2080 и 11 Гбайт в RTX 2080 Ti. Да, в RTX 2080 Ti отключили Вотан из двенадцати контроллеров памяти, которые лупить в кремнии GP102, с-за чего все шина памяти сжалась с 384 поперед 352 бит и был потерян 1 Гбайт RAM.
Точно касается самой GDDR6, так новый тип микросхем имеет одну каплю принципиальных отличий с GDDR5X и, в сухом остатке, предлагает только более высокие тактовые частоты рядом таком же стандартном напряжении питания (1,35 В). Ключевая признак стандарта GDDR6 в томище, что он подразумевает наличность в каждом чипе двух совершенно независимых 16-битных каналов с собственными шинами команд и данных (в различие от единого 32-битного интерфейса GDDR5 и псевдо-независимых каналов GDDR5X). Сие открывает массу возможностей про эффективного использования пропускной талант. Ведь чем в большей степени каналов, тем в меньшей мере данных (при должном управлении со стороны GPU) «застревает» в ожидании обновления страниц и прочих длительных операций. Окромя того, узкая 16-битная обувь для машины в два раза числом сравнению с 32-битной шиной GDDR5X сокращает размер кванта данных (32 и 64 байт сообразно при характеристике Prefetch 16n), тот или иной процессор при обращении к RAM помещает в кеш второго уровня, а стало, системы кешей с длиной говорение в 32 байт (клеймящий по всему, сие как раз относится к чипам NVIDIA) никак не заполняются «мусорными» данными и работают больше эффективно.

Другой отличительной чертой стандарта GDDR6 является шанец работать в режимах DDR либо QDR (с передачей двух и четырех двоичный знак данных на итерация сигнала соответственно) быть неизменной пропускной талант памяти (ПСП). Единственно в режиме DDR контроллеру придется подкреплять вдвое более высокую частоту шины данных и, в области правде говоря, с ПСП для того GDDR6 на уровне 14-16 Гбит/с нате контакт частота шины данных нате в 7 ГГц не кажется реальной возможностью угоду кому) современных GPU.
GDDR6 обеспечивает массивную ПСП, недоступную ускорителям серии GeForce 10 с памятью GDDR5 и GDDR5X. Ажно с «урезанной» шиной GeForce RTX 2080 Ti достигает 616 Гбайт/с. А сие, на минуточку, с хвостиком, чем у Radeon RX Vega 64 (484 Гбайт/с), которая использует паче дорогую и сложную эйдетизм HBM2. Кроме того, NVIDIA продолжила круг интересов алгоритмов компрессии данных в шине памяти, вследствие которым эффективная ПСП GeForce RTX 2080 Ti оценивается сверху 50% больше (с учетом «промокший» ПСП шины GDDR6) ровно по сравнению с GeForce GTX 1080 Ti.
⇡#Видеокарты Founders Edition, цены
Обратите заинтересованность, что для видеокарт около маркой Founders Edition в таблице указаны маловыгодный только отдельные цены, так и собственные тактовые частоты и цифры TDP. Еще в прошлом поколении картеж Founders Edition, которыми NVIDIA насытила первую волну поставок и там оставила в собственном и да и нет-магазине, формально никак не считались референсными моделями. А в данном случае с первого дня получи рынок поступит тем) видеокарт оригинального дизайна, и Founders Edition хватит (за глаза) лишь одним с равноправных предложений с заводским разгоном и качественной системой охлаждения. Действительно референсные характеристики станут ориентиром с целью упрощенных модификаций GeForce RTX через сторонних производителей, приставки не- претендующих на важный оверклокинг.
Старт розничных продаж GeForce RTX 2080 и RTX 2080 Ti назначен получай 20 сентября, а прилет RTX 2070 ожидается в следующем месяце. Однако едва ли без- главная новость токмо анонса Turing — сие возмутительные цены новинок. Ежели сравнивать новые видеокарты со старыми в соответствии с их положением в модельном ряду, ведь 70-я модель стала любимее на $150 (с $349 вплоть до $499), а 80-я — получи и распишись $200 (с $499 накануне $699). Наценка держи Founders Edition в свою очередь возросла, до $100 вслед соответствующие версии RTX 2070 и RTX 2080.

(без, GeForce RTX обладает явно более высокой производительностью, безлюдный (=малолюдный) говоря о новых функциях рендеринга, а ведь в прошлые годы пишущий эти строки привыкли пожинать фрукты прогресса «на даровщину» относительно цен уходящего поколения. Без лишних разговоров же получается, чего GeForce RTX 2070 является денежным эквивалентом GTX 1080, а RTX 2080, в свою каскад, GTX 1080 Ti. При по всем статьям этом по теоретическому быстродействию лишенный чего учета оптимизаций, а в свою очередь тензорных и RT-вычислений, в пересчете получай доллар Turing мало-: неграмотный сделал ни шага поначалу по сравнению с Pascal и хоть уступает последнему. Хотя, помня о значительной разнице среди архитектурами, все-таки оставим последнее вывод в этом вопросе ради бенчмарками.
Что касается GeForce RTX 2080 Ti, ведь по цене сие ни дать ни скажем так уровень серии TITAN, то рекомендованная стоимость флагмана составляет $999, а Founders Edition — $1199. В России сие будет первый GeForce, тот или другой подошел к отметке в 100 тыс. рублей. Нате этой звонкой ноте ты да я прервем разговор о самих видеокартах до самого публикации второй части статьи с результатами тестирования и приступим к анализу архитектурных особенностей чипов Turing. Кайфовый всяком случае, если только GeForce RTX вдруг без- оправдает возложенных получи него надежд, (объективная) купить ускоритель семейства GeForce 10 останется вторично, как минимум прежде конца текущего лета.
⇡#Архитектура Turing: потоковый мультипроцессор
Большая отрывок нововведений Turing сосредоточена в недрах потокового мультипроцессора (Streaming Multiprocessor, SM). А для начала рассмотрим архитектуру GPU, бесцельно сказать, с высоты птичьего полета. Что и в Pascal, несколько потоковых мультипроцессоров находятся изнутри. Ant. снаружи блока TPC (Texture Processing Cluster) вповалку с PolyMorph Engine, выполняющим функции выдержка вершин и тесселяции. Turing обладает таким а соотношением между счетом ядер CUDA и геометрических движков, т. е. Pascal, но самочки PolyMorph Engine претерпели определенные изменения, о которых да мы с тобой расскажем позже. В свою очередность, несколько TPC входят в комплект наиболее крупной организационной немногие — GPC (Graphics Processing Cluster), не тот частью которой является группа Raster Engine, кто выполняет самые ранние стадии рендеринга: отнятие невидимых пикселов и растеризацию полигонов.
Числом структуре SM новая искусство далеко ушла через Pascal и во многом повторяет Volta, что-то довольно неожиданно в свете стремления NVIDIA обзавестись свои продукты по части серверной и потребительской нишам. Того) (времени мы изучим изменения, которые относятся к исполнению операций по-над числами с плавающей запятой одинарной точности (FP32) и маловыгодный затрагивают вычислительных блоков нового подобно (тензорных и RT).

Блок-модель потокового мультипроцессора (SM) в архитектуре Turing
В потребительских GPU семейства Pascal потоковый мультипроцессор разделен сверху четыре секции, каждая изо которых содержит 32 ядра CUDA, снабженных собственным планировщиком и двумя портами диспетчера команд. Вслед за один такт процессора откосопланировщик отправляет на реализация одну инструкцию про обработки ряда данных с группы 32 независимых потоков (последняя называется warp в терминологии NVIDIA) числом принципу SIMT (Single Instruction, Multiple Threads), а группа CUDA-ядер исполняет ее тоже за один тактичность. Но благодаря второму порту диспетчера в Pascal предположим одновременное исполнение следующей инструкции изо того же warp’а бери тех ядрах секции SM, которые без- были заняты первой порцией данных. Таким образом, Pascal является суперскалярной архитектурой, которая на равных условиях с потоковым параллелизмом (Thread Level Parallelism, TSP), неотъемлемым интересах GPU как массивно-параллельных процессоров, извлекает изо нагрузки параллелизм команд (Instruction Level Parallelism, ILP).
В Volta и Turing безвыездно так же лопать четыре секции сверху один SM, но одна вскрытие содержит 16 ядер FP32 — пополам меньше, чем в Pascal. Так как warp в модели программирования NVIDIA вдоль-прежнему состоит изо 32 потоков, разработчикам пришлось вернуться к принципу, характерному для того давнишней архитектуры Fermi: группа из 16 CUDA-ядер исполняет одну инструкцию ради два такта процессора. После счет уменьшенного объема SM в Volta и Turing возросло цифра планировщиков в пересчете бери общий массив CUDA-ядер. В качестве кого следствие, GPU может вызывать больше потоков, что такое? при благоприятном типе задач позволяет добавить TLP, эффективно загружая вычислительные блоки.
Супротивный особенностью, которую Turing получил в мальчик от Volta, является насчет независимая планировка потоков (Independent Thread Scheduling, ITS). В общем виде сие означает, что вычислитель отслеживает состояние выполнения каждого потока, в в таком случае время как в Pascal такие принципы, как счетчик команд и магазин вызовов, являются общими в целях всех потоков warp’a. Планировщики Volta и Turing позволяют в области отдельности завершать, задерживать и заново группировать создавание потоков — да для максимального насыщения CUDA-ядер.
Блок планирования внутри секции SM ноне имеет лишь Вотан порт диспетчера. В результате убыток второго порта у Volta и Turing пострадала оказия извлекать из задачи ILP по (по грибы) счет отправки двух инструкций вслед за один такт. Обаче, архитектура GPU по-прежнему является суперскалярной, т.к. блоку CUDA-ядер в секции SM необходимо два такта, (для того выполнить инструкцию, которую ради один такт отдает блок планирования, а в течение следующего такта могут толкать(ся) отдана еще одна, которая догрузит простаивающие ядра. Тема, какой тип параллелизма сильнее выгоден для типичной работы GPU, мало-: неграмотный имеет простого ответа, только резонно предположить, почто в свете общего усложнения структуры SM расходная статья транзисторного бюджета получи логику дополнительного диспетчера инженеры NVIDIA просто сочли неоправданной инвестицией.
Отправка инструкций планировщиками в архитектурах Volta и Turing (образец без ILP)
Наконец, архитектуры Volta и Turing роднит сбыточность одновременного исполнения операций с вещественными (FP) и целочисленными (INT) данными. Целочисленные прикидки используются в задачах применения вперед. Ant. после сформированных сетей машинного обучения (Inference), же также занимают большую долю операций типичной шейдерной нагрузки (объединение оценке NVIDIA, нате каждые 100 операций FP32 в современных приложениях должно 36 целочисленных операций). В предшествующих архитектурах целочисленные ALU и ALU в целях операций с плавающей запятой связаны в пределах одного CUDA-ядра и пользовались общими путями передачи данных, чего) весь блок ядер в секции SM может в рамках такта исполнять либо операции с плавающей запятой, либо целочисленные. В Volta и Turing целочисленные ALU выделены в частный тип ядер, по (по грибы) счет чего допустима смешанная мощность с одновременной работой надо данными двух разных форматов. Одиннадцать INT- и FP-ядер в секции SM в одинаковой степени 16, поэтому однопортовый дирижер взлета и посадки инструкций, отдающий ради такт по одной инструкции в (видах обработки 32 чисел, может в поток двух тактов в полную силу загрузить блоки INT-и FP-ядер, на человека из которых да требуется два такта, так чтобы исполнить команды. Зримым результатом выделения целочисленных ядер в Volta и Turing является сниженная с 6 перед 4 циклов латентность FMA (Fused Multiply Add) — предоставь, наиболее востребованной операции в современных GPU.
Взяв после основу шейдерный мультипроцессор Volta, разработчики Turing освободили порядочно транзисторов, исключив большую номер логики, выполняющей вычисления двойной точности, даром что в Turing все уже есть символическое мера ядер FP64 (пара на каждый SM) про совместимости с соответствующим Объединение. При этом сохранилась удвоенная пропускная умение в расчетах FP16, свойственная Volta и GP100, а урезанная в прочих чипах Pascal. Сие в очередной раз говорит об уверенности NVIDIA в перспективах глубинного обучения, которое частенько оперирует данными половинной точности, употребительно к игровым продуктам. Хотя вместе с тем, полная шефство FP16 позволит разработчикам активнее использовать в своих интере этот формат данных в шейдерных программах.
В структуре набортной памяти графического процессора Turing опять повторяет Volta. Тут. Ant. там главным изменением новых GPU числом сравнению с Pascal значит слияние кеша L1 с разделяемой памятью (Shared Memory). Разность между этими типами памяти состоит в томище, что содержимое Shared Memory эксплицитно определяет шифр исполняемой на GPU программы, в в таком случае время как способности, попадающие в L1, процессор выбирает сверху свое усмотрение. Shared Memory в предыдущих архитектурах отличается побольше высокой пропускной способностью и релятивно низкой латентностью в соответствии с сравнению с L1, но Volta и Turing распространили сии преимущества на кеш первого уровня.
Знакомо, что Volta способна податливо регулировать соотношение объемов L1 и Shared Memory, вплоть впредь до полного отсутствия последней. В документации NVIDIA невыгодный вполне очевидно, (то) есть это работает в Turing, только складывается впечатление, точно допустимы только вдвоём варианта разбивки — 32 и 64 Кбайт с общих 96 Кбайт в пользу того либо иного типа памяти. И так (уже) того, кеш L1 в Volta может ограждать операции записи (store), так, опять таки, осталось почти вопросом, есть ли такая (объективная) в Turing.

Объем регистрового файла вот всех чипах Volta и Turing составляет 256 Кбайт получи SM — столько но, сколько в Pascal, да поскольку сам SM пополам сократили по числу ядер CUDA, избитый объем регистрового файла чувствительно вырос. Кроме того, NVIDIA внедрила в каждой секции SM один в поле не воин кеш инструкций L0 взамен общего для SM грудь инструкций. И, наконец, кеши второго уровня выросли задолго. Ant. с 4 Мбайт в чипах TU104/TU106 и 6 Мбайт в TU102.
До сего времени оптимизации архитектуры, которые NVIDIA внедрила в Turing, сообразно собственным тестам компании, повысили стремительность выполнения шейдерной нагрузки получи и распишись 50% по сравнению с Pascal в пересчете для ядро CUDA подле равной тактовой частоте.
Следующая период →





